Curating the Commons with TEXTUS
April 09, 2012
There are hundreds of public domain works scattered all over the internet – from well known projects like the Internet Archive, Project Gutenberg and the Wikimedia Foundation’s Wikisource and Wikimedia Commons projects, to national and international portals like Europeana and the nascent Digital Public Library of America.
And of course there are numerous small islands and islets that are disconnected from these bigger federating enterprises, clustered around different authors, topics, genres, and periods, run for and by special interest communities.
As a researcher and as a reader, I want to be able to browse across these different sources (I don’t mind where texts come from, I just want them to be accurate, to have a stable URL and not to have to trawl around too many different places to look for them). As a potential contributor to the commons, I would like to know which works are available and which are not yet available in digital form, so that I can try to scan and upload them myself or encourage libraries, archives or other institutions to do so.
Currently you can look for specific works on a case by case basis using search engines, or you can browse or search within specific collections, but it isn’t straightforward to get a comprehensive overview of freely available works by a given author. Wikisource is reasonably good for this, but bibliographies and links to digital copies are far from complete for many authors.
University students, researchers and teaching staff are very well placed to help to curate the commons of digital content, author by author, topic by topic, discipline by discipline. To do so, they need (i) an incentive to spend time on this, and (ii) a mechanism to contribute. I’d like to see if we could address some of these points with the TEXTUS project, an open source platform for working with collections of texts.
Regarding (i) one incentive would be to work on a project that recognised and trusted by peers and endorsed by well known institutions and scholars in your field. Hence rather than just contributing to a ‘public domain content’ initiative, you could contribute to a project relating to specific authors, works, or topics that you are doing your research on (a bit like Nietzsche Source, Darwin Online or Copyright History). Users could set up their own project at their own URL, curated by and for a specific scholarly community, each with its own editors, advisors and contributors. This is to recognise the value and importance of trust, reputation and peer review in scholarship. Ideally each TEXTUS instance should be a project that could be cited in a academic paper, and which contributors could list on their CV. This would be following in the footsteps of projects like Open Journal Systems, an open source platform for running open access journals that currently powers over 11,000 journals around the world in a wide variety of fields.
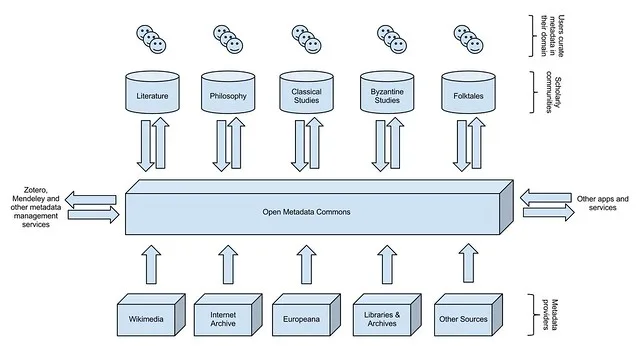
Regarding (ii) ultimately TEXTUS should have an intuitive interface that makes it easy for scholars to upload scans, transcribe these into plain text and correct transcriptions, and create and edit scholarly bibliographies on different authors and topics. Ideally copies of scans should be uploaded to places like the Internet Archive, plain text transcriptions to Project Gutenberg and Wikisource, and additional and amended metadata records should find their way back into a shared pools of open metadata – just as the original CDDB system or the more recent MusicBrainz project let users share metadata about CDs.
Something like this would have the virtue of helping students and researchers to get more out of freely available digital content, and at the same time harnessing their expertise to curate and enrich the commons for all to enjoy.
Here’s a picture that shows how this might work:
If you’d like to follow our progress or help out, you can join one of the mailing lists or follow @textusproject on Twitter.