New Article: “Redistributing Data Worlds: Open Data, Data Infrastructures and Democracy”, Statistique et Société, 5(3)
January 28, 2018
I’ve just had an article published in the latest issue of Statistique et Société, a journal dedicated to exploring “how statistics intervenes in society, plays a role that is often unnoticed, and is in turn transformed by it”.
The article is titled “Quand les mondes de données sont redistribués : Open Data, infrastructures de données et démocratie” (“Redistributing Data Worlds: Open Data, Data Infrastructures and Democracy”).
You can download the French PDF here and the English version here. The text of the article is also copied inline below. The full reference is: Gray, J. (2017). Quand les mondes de données sont redistribués: Open Data, infrastructures de données et démocratie. Statistique et Société, 5(3), 29–34.
Statistique et Société is an open access journal run by the Société Française de Statistique (French Society of Statistics). It is edited by Emmanuel Didier (CNRS/EHESS), a leading researcher on the social and historical study of statistics. It includes scholars such as Theodore Porter on its advisory board.
Redistributing Data Worlds: Open Data, Data Infrastructures and Democracy
Jonathan Gray, King’s College London
For centuries human beings have invented methods and instruments for taking account of different aspects of the world through numbers. Making data about people, places, resources and things has become an indispensable part of the fabric of collective life and efforts to map and shape it.
The apparent power and transformational potential of such numbers has long inspired wonder, concern and action of various kinds, both for better and for worse. Data is imagined and used to understand, steer and refashion the world, whether in the service of boosting economic growth or redistributing resources; exploiting natural resources or conserving ecologies; promoting public health and education or cracking down on crime or dissent; turning land into territory and people into citizens, consumers, workers, comrades or suspects. Accounts of such projects can be found in a growing literature of histories and sociologies of quantification and statistics.1
What happens to these social practices and imaginaries of quantification when readily available digital technologies facilitate the creation, analysis and reproduction of data by different publics? What kinds of shifts, dynamics, controversies, visions and programmes can be observed when data goes digital? One recent answer to these questions can be found in the phenomenon of open data, which can be understood as set of ideas and conventions aiming to turn information into a re-usable public resource.
Through open data practices and initiatives, the by-products of administration, governance and other activities of public institutions can be transformed into a “raw” resource – variously described as the “new gold”, the “new oil” or the “new soil”. This is pursued through a series of legal, technical and social conventions which are intended to make data public in order to catalyse various forms of innovation beyond and across the public sector. These conventions draw upon a constellation of cultures and norms associated with open source, free software, free culture, civic hacking, data journalism, linked data, agile software development and web 2.0 communities. Following Howard Becker’s analysis of the conventions which hold “art worlds” together (Becker, 1984), what kinds of “data worlds” do these open data conventions support?
Some of these conventions aim to make data legally and technically re-usable. Thus open licenses, legal regimes and information policies aim to mitigate the effects of copyright and database rights which may inhibit the re-use of public data by clarifying that it may be legally re-used without payment or permission – drawing on legal practices associated with free/open source software, free culture, open access and open science groups. There are strong norms for publicly documented, accessible, structured file formats, prioritising “machine readable” data formats such as comma-separated values (CSV), JavaScript Object Notation (JSON) and Excel spreadsheet (XLS) formats over print layout formats such as the PDF.
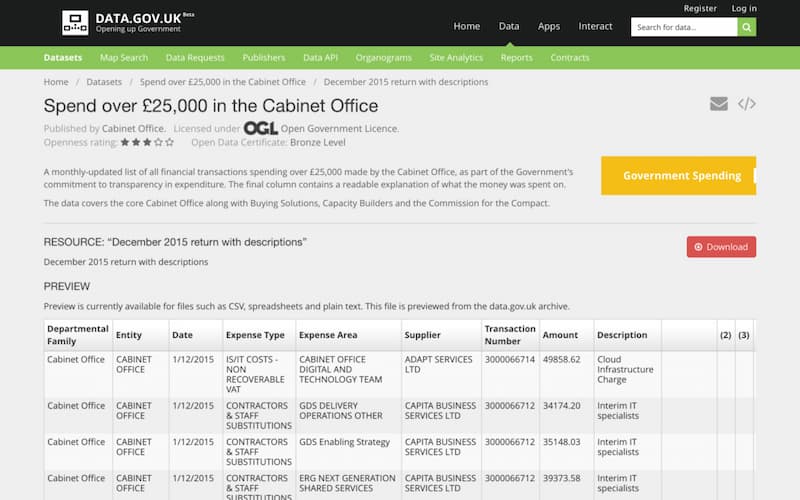
There are also hundreds of local, regional and national data portals from states, citizens, NGOs and companies which aggregate data from different sources in order to make it easier to find and re-use. For example, Figure 1 shows a page from the data.gov.uk data portal which is dedicated to spending data from the UK’s Cabinet Office, which shows the open license promoting re-usability, as well a preview of structured tabular data which can be downloaded.
There are hackdays and hackathons, intended to promote re-use of open data – as well as fellowships, challenges, incubators and labs to promote innovation and collaboration. These have given rise to hundreds of apps, data projects, interactives, prototypes, websites and digital products and services which use this open data to various ends – whether through creating new maps, data visualisations, data stories and “data investigations” or through personalising, customising, narrating, filtering and combining information in other ways.
These developments have been propelled forward by different visions of what might happen by opening up official data. Some suggest that this can improve the transparency and accountability of public institutions – e.g. to create projects that show how public funds are spent. Others say that data will help increase public sector efficiency and reduce costs, by enlisting “armchair auditors” to identify waste and by allowing and encouraging non-state actors to produce websites and services which would otherwise be produced with public funds. Others contend that public data can be used to create websites and projects which strengthen democracy – e.g. by allowing citizens to contact public institutions or politicians or coordinate around civic or collective tasks. Others maintain that data can be used by new businesses, technology companies and start-ups to create jobs and stimulate economic growth. Open data can thus be understood as a malleable concept which is reconfigured to align with different conceptions of public institutions, markets, and social life (Gray, 2014).
How does open data shape social practices of quantification? Here we may look beyond the datasets that open data advocates valorise as raw material for innovation, and back towards the data infrastructures through which these datasets are created. Following other scholars of information infrastructures, these data infrastructures may be viewed as socio-technical arrangements which underpin the production of data: consisting of relational ecologies of software components, data standards, methods, techniques, committees, researchers, instruments and other things (Bowker & Star, 1998, 2000; Star, 1999; Bowker, Baker, Millerand, & Ribes, 2009). We may also look at the data worlds which datasets are part of – including how data infrastructures make it possible for different actors to see, engage with and relate to things in different ways (Gray, 2018).
Open data enables and promises different forms of redistribution and reconfiguration of these data infrastructures and data worlds – from social democratic visions of participation in public institutions and public service delivery, to information policies which seek to limit the role of the state to providing “raw” data which non-state actors can then use as the basis for information products and services (Gray, 2014). For a start, the digital distribution of data means that the number of people who are able to access and use it is, in principle, multiplied to include anyone with an internet connection and the requisite background knowledge to use it. Commodity database and data storage, analysis and visualisation technologies mean that the contexts of usage of public sector data can extend far beyond the statisticians, administrators, managers, researchers and civil servants who are involved with its production and use in public institutions. New “styles of reasoning” (as Hacking puts it) and new genres of sense-making are rendered possible – as data moves from policy reports to mobile apps and interactive online graphics.
As datasets are recombined, extracted, hybridised, reformatted, reconstructed, re-use and given different meanings by new actors – new data worlds emerge. The redistribution of these data worlds can be understood in at least three ways (Gray, 2018).
Firstly, we might consider the redistribution of data worlds in terms of changing the composition the social worlds of “data experience” and “data work” as a distributed, collective accomplishment. Open data initiatives aspire to bring about redistributions in the collectives associated with public information, explicitly reaching out to new actors beyond the public sector (whether citizens, civil society groups, students, researchers, journalists, start-ups or technology companies) through mechanisms such as social media channels, meetups, mailing lists, labs, incubators, hackathons, fellowship schemes, crowdsourcing initiatives, apps, data projects, data “sprints”, data “expeditions” and dedicated websites. Data portals invite users to download public data and make their own apps, visualisations, websites and services. Open data initiatives aim to harness the wisdom of the crowd, the expertise and experience of different actors outside the state to, as one UK government initiative put it: “Show Us a Better Way”.2
Thus we might examine both the practices and imaginaries of public participation, public engagement, co-design and innovation around public data – and the effects of these shifts, from new political economic configurations to emerging forms of public space, mobilisation, societal controversy and issue formation. We can see how it is envisaged that these redistributions will occur, for example, by examining “data imaginaries” and “data speak”. We may also look at what kinds of social collectives – “data publics” – are actually assembled around public data in practice, as well as what the politics and patterning of devices and procedures of public involvement, and which kinds of publics they include and do not include.
Secondly: we may consider redistributions in the composition of data worlds in terms of changing how things are rendered intelligible: providing conditions of possibility for experiencing, understanding, interacting with and making sense of the world. To paraphrase Bruno Latour: change the instruments, and you will change how things are seeable, sayable and doable with data. Here we can look at the new meaning-making practices associated with open data – including aggregating and combining data from different sources; through the use of machine learning, algorithms and new analytical techniques; through the creation of new kinds of data visualisations and “data experiences”; or through technological products and features which facilitate different modes of relating to data – such as through online platforms, mobile apps, geolocation, tagging, annotation, crowdsourcing, real-time notifications, augmented and virtual reality, wearable technologies and immersive multimedia installations.
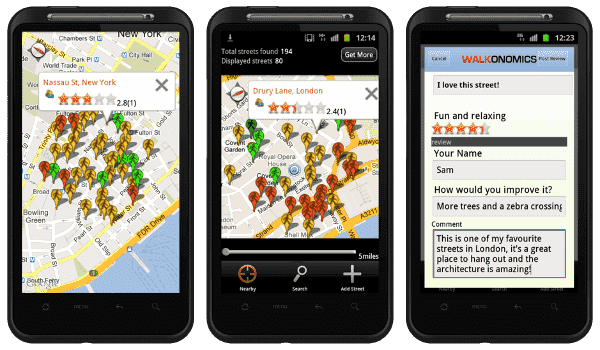
Open data thus not only changes who can use different representational resources about the world, but also facilitates new kinds of creative practices for making sense of collective life. For example, the “Walkonomics” app (Figure 2) combines multiple sources of open public data with user generated data in order to provide ratings for the “walkability” of different regions and routes in several major cities – providing a new device for collectively quantifying, ranking and relating to urban places.3
Thirdly: we may look at how open data changes data worlds in terms of the reshaping of the relations, alliances and territories of political world-making projects (and perhaps more recently – world-unmaking projects), as per recent research on the sociology of the transnational circuitry of globalisation. Transnational open data projects facilitate new regimes of transnational quantification and the aggregation, harmonisation and standardisation of data.
For example, Open Street Map enables users to add geospatial data from a wide variety of sources – from public sector agencies to data that they have collected themselves or traced from maps.4 The Open Contracting Partnership creates new standards in order to enable “shareable, reusable, machine readable” public sector contracting data which is aligned and comparable across borders.5 The Open Spending aggregates millions of spending transactions from over 70 countries.6 Open Ownership aims to create a new global register of “who controls and benefits from companies”.7 These cases may be construed as new transnational networks of expertise, exchange and knowledge transfer in order to align and standardise “data work” across borders.
By way of concluding this short missive, I hope that these three ways of looking at the redistribution of data worlds – in terms of social collectives, meaning-making practices and transnational networks – will help to draw attention to different aspects of the politics of open data and public information, and how digital technologies are giving rise to different social practices and styles of quantification. Whilst the open data rhetoric often emphasises the “liberation” of pre-existing public sector data in order to fuel innovation and the extraction of value, this is not without translation, mediation and new kinds of social practices and social worlds. The transposition of data from the public sector to various other actors is giving rise to new kinds of “data worlds”.
In some cases, pre-existing and sometimes long entrenched public data infrastructures and practices may “parameterise” and give structure to novel forms of data experience. For example, fiscal data standards from international organisations shape the spending categories which are rendered into interactive data visualisations and experiences – creating innovative information products which nevertheless reinforce certain ways of looking at and thinking about fiscal policy. In other cases emerging “data publics” may attempt to reshape public data infrastructures or create their own as an emerging form of digital “issue work”. Thus, for example, journalists and activists have recently created their own databases of police killings, migrant deaths, pollution events, literacy measurements or water supply evaluations as a means to change how different issues are collectively taken into account through data (Gray, Lämmerhirt, & Bounegru, 2016).
A movement which started life calling for opening up official datasets may yet contain the seeds of a more ambitious political programme to open up public space, imagination, participation, deliberation, contestation and creativity around the making of data (Gray, 2016). What could be read in terms of a tendency for a grassroots institutionalisation of certain styles of reasoning, modes of experiencing and genres of quantifying issues (inherited as a by-product of administration and governance in the public sector) could nevertheless serve as the basis for more rich and meaningful democratic deliberation around what and how things are taken into account through data, and with what effects. At a time when public trust in institutions is said to be waning and yet the scale of the large, collective issues that we face is considered to be without precedent in modern times, such public experimentation around the role of data in democratic societies is surely to be welcomed. While the study of open data does indeed suggest ways in which it may be used as a means to accelerate and socially institutionalise different forms of marketisation and bureacratisation, it may also sometimes reward us with reminders that other data worlds are possible.
Notes
References
Becker, H. S. (1984). Art Worlds. Berkeley, CA: University of California Press.
Bowker, G. C., & Star, S. L. (1998). Building Information Infrastructures for Social Worlds — The Role of Classifications and Standards. In T. Ishida (Ed.), Community Computing and Support Systems (pp. 231–248). Springer Berlin Heidelberg.
Bowker, G. C., & Star, S. L. (2000). Sorting Things Out: Classification and Its Consequences. Cambridge, MA: MIT Press.
Bowker, G. C., Baker, K., Millerand, F., & Ribes, D. (2009). Toward Information Infrastructure Studies: Ways of Knowing in a Networked Environment. In J. Hunsinger, L. Klastrup, & M. Allen (Eds.), International Handbook of Internet Research (pp. 97–117). Springer Netherlands.
Bruno, I., Jany-Catrice, F., & Touchelay, B. (Eds.). (2016). The Social Sciences of Quantification: From Politics of Large Numbers to Target-Driven Policies. New York: Springer.
Desrosières, A. (2002). The Politics of Large Numbers: A History of Statistical Reasoning. (C. Naish, Trans.). Cambridge, MA: Harvard University Press.
Espeland, W. N., & Stevens, M. L. (2008). A Sociology of Quantification. European Journal of Sociology / Archives Européennes de Sociologie, 49(3), 401–436. <https://doi.org/10.1017/S0003975609000150>
Gray, J. (2014). Towards a Genealogy of Open Data. Presented at the European Consortium for Political Research (ECPR) General Conference 2014, University of Glasgow. <https://dx.doi.org/10.2139/ssrn.2605828>
Gray, J. (2016). Datafication and Democracy: Recalibrating Digital Information Systems to Address Societal Interests. Juncture, 23(3). Retrieved from <https://www.ippr.org/juncture/datafication-and-democracy>
Gray, J., Lämmerhirt, D., & Bounegru, L. (2016). Changing What Counts: How Can Citizen-Generated and Civil Society Data Be Used as an Advocacy Tool to Change Official Data Collection? CIVICUS and Open Knowledge. https://dx.doi.org/10.2139/ssrn.2742871
Gray, J. (2018). Three Aspects of Data Worlds. Krisis: Journal for Contemporary Philosophy.
Hacking, I. (1985). Making People Up. In T. C. Heller, M. Sosna, & D. E. Wellbery (Eds.), Reconstructing Individualism: Autonomy, Individuality and the Self in Western Thought (pp. 222–236). Stanford, CA: Stanford University Press.
Porter, T. M. (1986). The Rise of Statistical Thinking, 1820-1900. Princeton, NJ: Princeton University Press.
Porter, T. M. (1996). Trust in Numbers: The Pursuit of Objectivity in Science and Public Life. Princeton, NJ: Princeton University Press.
Rottenburg, R., Merry, S. E., Park, S.-J., & Mugler, J. (Eds.). (2015). The World of Indicators: The Making of Governmental Knowledge through Quantification. Cambridge: Cambridge University Press.
-
See, for example, Hacking, 1985; Porter, 1986, 1996; Desrosières, 2002; Espeland & Stevens, 2008; Rottenburg, Merry, Park, & Mugler, 2015; Bruno, Jany-Catrice, & Touchelay, 2016. ↩
-
See: https://www.walkonomics.com/ and https://data.gov.uk/apps/walkonomics-find-walkable-route ↩